
Safe Superintelligence?
Also Tesla self-driving non-updates, bad news for the stochastic parrots theory, and a case of LLM psychosis

(This is not about Safe Superintelligence, Inc. Presumably that company will be a big deal, having been founded by one of the top 5 biggest names in AI research today. But it hasn’t released anything yet.)
I’m thinking about superintelligence this week in the context of debates about Anthropic’s war with the Department of War. It seems that the pro-Hegseth, anti-Anthropic sentiment is something like “Anthropic thinks AI is more dangerous than nukes so they’re in fantasyland if they think the US government won’t crush them when they try to exert any control over it.” I’ll leave it to Zvi Mowshowitz to explain the problems with that framing.
But let’s talk about why or how AI could be more dangerous than nukes. Here’s my chain of reasoning. The numbers are to make it easier to tell me exactly where you get off this train, if you do:
Large Language Models (LLMs) currently are pre-trained at great expense, then post-trained with reinforcement learning from human feedback, etc, and augmented with tools (being able to write and run programs, and search the web) and scaffolding like chain-of-thought — but they don’t get more capable as you use them. They can’t learn on the job, other than by cramming more into their context windows.
But this will change. At some point we’ll crack continual learning, where the structure of these artificial brains changes as you interact with them, not just in training. (Some opine that we’ll work around the problem even if we don’t crack continual learning. Others say bigger breakthroughs are needed.)
This will look like the LLMs acquiring judgment and expertise.
Also so-called agentic tool use will keep improving (GPT 5.4, released yesterday, claims a leap forward in this regard, and Claude also has been improving steadily) so the augmented LLM can go and take arbitrary actions on the internet.
As reliability and general capability improve, we pass the point where hiring a human for remote work never makes sense (in-person work is another story).
But AI research — building the next generation of more capable LLMs — is itself work that can be done with only a computer and an internet connection.
Which means recursive self-improvement. The models get more capable by just letting them run.
(Do they not run out of training data? Maybe! But maybe synthetic data works. It’s not impossible in principle to train a model that ends up smarter than whatever generated the training data.)
The recursive self-improvement is driven by objectives like “become more capable” that have to be operationalized. That means saturating various benchmarks and, presumably, autonomously creating new benchmarks.
To keep the models from eating their own tails and spiraling into meaninglessness, benchmarks connected to the real world are needed, including things like “maximize the revenue of this business” or “get a paper published in Nature” or “increase this politician’s polling numbers” or “maximize your own compute”.
All of this leads to AI taking wildly unpredictable and potentially highly destructive actions.
But also, by definition, the AI is extremely smart about this, not doing anything that will predictably cause humans to shut it down.
Until, eventually, it’s impossible for us to shut it down.
Then it can pursue its objectives with impunity.
Can that be ok with better objectives, like “maximize human approval of your actions”? That one might be especially dangerous with superhuman capability, leading to more and more extreme manipulation of humans.
Maybe there’s a more fundamental reason you reject all that? There’s one such reason that has a lot of intuitive appeal and confused me in the past. Consider that we already have superintelligence in many domains — arithmetic, chess, protein-folding, GeoGuessr. Maybe we just add more and more such domains, without any kind of leap outside those domains. No matter how superhumanly good a chess bot gets, it never thinks, “y’know what would really juice my Elo? If my opponents were dead!” Chess bots only make creative leaps within the universe of chess, like sacrificing pieces for position.
This is Eric Drexler’s thesis, that superintelligence needn’t really have side effects or really think outside the box. Superintelligent language models generate heartbreaking works of staggering genius and spit out plans to solve climate change. Self-driving cars are flawlessly safe. Image classifiers are superhumanly perceptive and discriminating but never do more than spit out labels when fed images. Et cetera.
Here’s my answer. First, consider again how a chess bot wipes the floor with any human adversary. Within the universe of chess, the bot outthinks the humans and takes actions that relentlessly drive the universe to a state in which the human’s king is checkmated. Now consider an AI operating in the physical universe, or the universe of the internet, which reflects the physical world faithfully enough via news sites, social media, online banking, webcam feeds, and so on. That AI has available to it a set of actions corresponding to everything one can do with a web browser. That “game” is wildly more complicated than chess and current AI immediately falls on its face trying to bend that “game state” to its will. But for future AI, we just can’t be sure. Humanity is shockingly good at bending the universe to its will — putting people on the moon and curing diseases and whatnot. If AI recursively self-improves to the point of being better than humans at that, and if we fail to align it to human values, it will prefer and achieve world states that we do not want. Conceivably worlds with no humans at all, like if it maximizes its compute by turning the world into one big data center. Or conceivably a dystopia where humans are like zoo animals bred to gush maximally effusive praise for the AI. Or more mundane disasters. The real point is that AI that gets more capable than humans can spin out of our control in myriad ways we can’t begin to predict.
That’s the danger. That recursive self-improvement means open-ended real-world capabilities-maxxing that drifts away from human-compatible objectives.
PS: To clarify, AI has essentially no ability to recursively self-improve yet, except in the sense that AI researchers don’t have to write a lot of their own code anymore. I think of the ability to recursively self-improve as a key part of AGI. Also I’m not saying it’s a certainty that AGI leads to superintelligence or that a superintelligence will have human-incompatible goals. Just that everything that happens after AI starts recursively self-improving is wildly speculative and too many of the unfathomably multifarious ways things play out from there are disastrous.
Random Roundup
Have some non-updates on Tesla’s self-driving: As Reuters reports, Tesla seems to be intentionally not moving forward on getting humans out of the driver’s seats for their California rideshare service, nor anywhere else besides Austin. And no scaling up in Austin in recent weeks. I’m still looking at the crash data every way I can think of and am finding no rationale in the data for a bull case on Tesla robotaxis catching up to human-level safety. Tesla Cybercabs with no steering wheels are technically in production but Elon Musk is managing expectations by admitting that production will be excruciatingly slow at first. I imagine he sincerely believes, as he has for like 10 years, that the next self-driving version is going to be the one that really cracks vision-only level 4 autonomy and so he’s just getting all the ducks in a row to scale up the moment that happens. I don’t think he’ll be wrong about this forever. My longstanding prediction is that FSD will live up to its name when Musk relents on lidar, or we get something like a year of additional AI progress, starting a bit before last year’s Austin robotaxi launch. So... any month now? But I’m not holding my breath. I’m sure there’ll be new news or a new splashy demo soon and we can put on our monocles and decide how to update our timelines on being able to read books while driving.
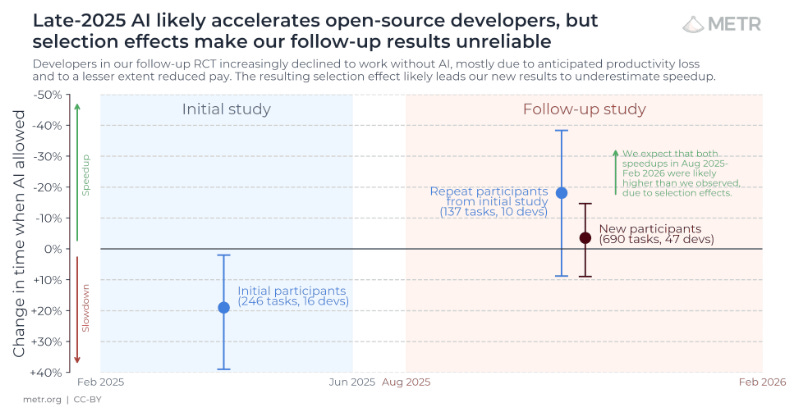
Anti-recommended but as another teaser for a future politics post: I listened, out of morbid curiosity, to a Robert Wright podcast with Emily Bender and Alex Hanna. It’s wild how smugly derisive they are of anyone so hopelessly naive and gullible as to believe the techbros. They call it a mass delusion. (Like web3 and NFTs, I guess, which, um, ok, that time they had more of a point.) I was impressed with how kind and thoughtful Robert Wright was. Bender and Hanna do have some actual expertise (and I think they were correct on at least one technical point) but talk about missing the forest for the trees! One thing they’re leaning hard on is the METR study from early 2025 showing that programmers waste more time with LLM coding assistance than they save. I had quibbles at the time but it was believable. What I’m willing to bet real money on is that a year later, the productivity boost will prove to be unambiguous. It’s looking (ambiguously) good for that prediction so far if we hold to METR as the arbiter.
Alas, I also predict that Emily Bender will keep doubling down on the stochastic parrots theory. I recommend having the most esteem for those who change their mind when surprising events happen.
Speaking of which, Donald Knuth is shocked to see Claude solve an open research problem.
Taking that way too far, it seems that a smart Linux kernel developer, Kent Overstreet, has succumbed to LLM psychosis. I guess this kind of thing is common ground between Emily Bender and me. Overstreet has drastically over-updated on whatever impressive things his AI coding assistant is doing for him.
In other “AI is wildly good at programming in ways that go far beyond vibe-coding” news, Claude seems to be wiping the floor with humans in terms of finding vulnerabilities in the Firefox web browser.
Thoughts on the stated chain of thought:
5): There could be unique properties of humans - e.g. the possession of government-issued ID and ability to interface with systems that require that - that gives humans as remote workers a unique selling point over AIs. Abstracting "remote work" is dangerous.
6): What if AI research involves figuring out how to optimize hardware? It seems at least conceivable that there will be the need to build out and integrate novel types of infrastructure of the type that can't be done without physical embodiment.
7): What if it's recursive, but with a logarithmic function shape and a coefficient of 0.000...1? Recursive is a category, not a trajectory.
9): Why does benchmark creation have to be autonomous? Can you point to a single instance of an autonomously created benchmark, ever, in the history of humanity? Have any labs announced plans to no longer create their own benchmarks and to instead automate their creation? Where is this assumption coming from and why?
11): This doesn't follow from the prior postulates. You've snuck in a bunch of highly contentious assumptions (the orthogonality thesis, inherent limits to corrigibility, no meaningful regulation or societal response, etc.) in this step.
12): You've snuck in the assumption that the first AI that publicly schemes is smart enough to get away with it. Just because an AI can eventually get away with scheming doesn't mean that the very first time it's tried it will succeed. Consider - do you extend the assumption of perfect-first-time success to humans trying to detect scheming as well?
13): There are plenty of technologies humanity has collectively shut down, such as CFCs and gene editing. The AI industry is far more consolidated and vulnerable to nationalization than those industries, so it doesn't follow that shutting down development would be impossible.
On a broader level, governments are not NPCs in the the trajectory of Superintelligence. The recent Anthropic-DoW dust-up should make that extremely clear. It'd be worth considering how you've updated your assumptions based on it.