
Nothingburgers and a Man vs Machine Hackathon
Let's hear the pessimists out, and make more predictions

Are LLMs hitting a wall? Do they actually save programmers any time? Was GPT-5 a nothingburger? I think one reason these questions are so divisive is that LLM intelligence is so spiky. As Scott Alexander put it, “in any given area, it seems like almost a random draw whether they will be completely transformative or totally useless.” If you’re extremely bearish or bullish on AI, it’s worth keeping in mind that your experiences might be pretty atypical. [Added the next day: And if you hate AI so much that you haven’t tried it since ChatGPT debuted, you’re in for a shock.]
Scott also has the best answer I’ve seen to the GPT-5 nothingburger question. Namely, that ChatGPT o3 was the model that was genuinely revolutionary. If OpenAI had called it “GPT-5”, the hype and reality would’ve been reasonably aligned. “Instead,” says Scott, “they called it ‘o3’, and called a minor incremental update a few months later ‘GPT-5’. Then people got mad that the exciting-sounding ‘GPT-5’ was merely an incremental update.” Amen. Personally, I was blown away by o3 enough to wonder if OpenAI had entirely solved the problem of chatbots exhibiting egregious failures of common sense. (Answer: no but it’s getting closer.) Furthering the confusion, GPT-5 is multiple models in one and ChatGPT tries to be clever about routing your prompts to the right sub-model. I recommend explicitly selecting GPT-5-Thinking for everything. When I do that, I do think GPT-5 is a genuine upgrade even over o3. I’m failing to find GPT-5 failures as bad as the duct-taped ham sandwich question o3 fell on its face on. (That’s now being debated in another Manifold market, of course.)
Hallucinations are another story, but my own sense is that that’s steadily getting better too. In fact, I have a new prediction: Even if LLMs have already hit a wall, it will, within two years, be reasonable to cite a chatbot’s answer to a factual question without mentioning primary sources. Chatbots will (correctly) be viewed as being as authoritative and reliable as Wikipedia is currently. If that doesn’t happen from improvements in the LLMs themselves, I think it will happen via LLM scaffolding, where another LLM automatically fact-checks the answer before giving it to the user. In the meantime, I recommend the “My Mate Dave” test.
What about LLM coding assistance? A couple months ago, I talked about the METR study suggesting that programmers who think LLMs are saving them time are delusional. This has been a topic of heated debate among my friends and colleagues ever since. The latest salvo is a post by Mike Judge claiming empirical evidence (both via his own experiment, and looking at data on the amount of software getting shipped) that the LLM revolution is not actually helping programmers.
As with AI more broadly, it’s wild how different different people’s experiences with code assistants are. I do think there are some highly impressive people, working in specific areas, who know their tools inside and out, whom LLMs slow down. They should take that Mike Judge article to heart and be pickier about what they ask the LLM to write. If you’re a real wizard, maybe only talk to the LLM about your code rather than ask it to write it. But I think even wizard ninja rockstars can get big benefits from an LLM chiming in about likely bugs or better ways to do things. You can ignore it if it seems wrong to you but sometimes — enough of the time — you’ll be like “ooh, good catch” or “wow, I didn’t know about such-and-such trick”.
In fact, I’m going out on a limb with another prediction: The pessimistic results about LLMs slowing coders down won’t replicate under the following conditions:
The programmers have time to get comfortable with LLM-assisted coding.
They’re using the latest/greatest models. It’s only been 3-7 months since METR ran their study but I do think LLMs have gotten smarter since then.
The programmers are warned that other programmers are commonly slowed down by the LLM — e.g., getting distracted while waiting for it, or endlessly cajoling it when it’s just not smart enough to do something.
Consider: Does it actually make sense for an LLM to literally slow a programmer down? With a bit of self-awareness you’d notice that and just not use it. So, y’know, acquire that self-awareness and only use the tool when you expect it to help. Does Mike Judge think that that will be never? If so, he’s missing something big.
And guess what? We’re getting another test of this tomorrow, at the Man vs Machine hackathon, in which teams will be randomly assigned to either use or not use AI coding tools. I’m betting on the machines.
Random Roundup
As a followup to an item in last week’s roundup, on GPT-5 extending the frontier of new math, we have a brand new paper discussing the pros and cons of LLMs as math research assistants. Key except, also relevant to the nothingburger discussion above: “The improvement over GPT-3.5/4 has been significant and achieved in a remarkably short time, which suggests that further advances are to be expected. Whether such progress could one day substantially displace the role of mathematicians remains an open question that only the future will tell.”
Oh my goodness the hilarity that is “What Is Man, That Thou Art Mindful Of Him?”. I liked it so much I got our household to do a dramatic reading of it. No recording, sorry. Presumably it will be on the ACX Podcast soon. I believe it captures the current debate about AI quite… faithfully.
The hardcore pooh-poohers believe AI is a bubble. Skyrocketing valuations of AI labs don’t contradict that but are you persuaded by Anthropic going from $1 billion a year in annualized revenue at the start of 2025 to $5 billion as of last month? Gary Marcus can explain it away, I’m sure, but it should at least give you pause.
UPDATE 6 months later (2026-02-23) on that last bullet point about AI company revenue (note the logarithmic scale):
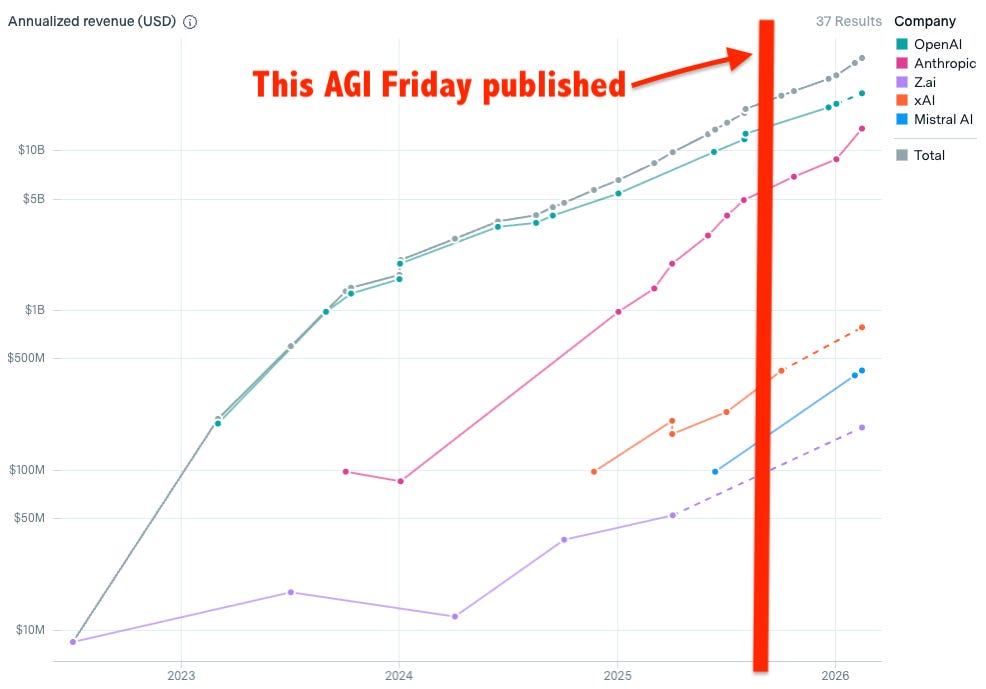
Not that this proves the pooh-poohers wrong. But if they’re right then the longer this continues the more catastrophic the crash will be.