


Erdil the Bull Predicts Unpredictability
Also we let Claude whip us up a new UI for the NYT Connections game

Happy Friday and happy Pi Day. I’m late posting this and had to pay Beeminder $5, oops. In further embarrassing news, despite playing with GPT-4.5 all week I still can’t decide what my verdict is. It’s not blowing me out of the water, in any case. I continue to think normal people should stick with Claude.ai. Claude is widely considered best at writing code (more on why normal people might care about that below) and is close enough to the frontier at explaining jokes or writing poetry or whatever else you might ask of it. Homework, up to college-level or so, is rapidly becoming a solved problem, so to speak.
So what about the big question from last week, whether the relative disappoint of GPT-4.5 means that LLMs are hitting a wall? I’ll tell you: I still don’t know. I continue to have whiplash. I mentioned last time a bear case that sounds compelling. I was nodding along and then I read a bull case from Ege Erdil that, well, restored my uncertainty at least. Here’s my summary:
Asking what fraction of the way to AGI we are is very hard and our estimates unreliable. What's historically worked better at predicting AI progress is first-principles reasoning. Like Kurzweil famously did in 1999. Estimate the brain's computational power and just extend lines on log-plots, follow Moore’s law, and see when we expect computers to be that powerful. Erdil also has an elegant-sounding theory about how to predict, based on evolutionary principles, what will be easy vs hard for AI — basically a generalization of Moravec's paradox.
(The short version of that is we should expect the hardest tasks for AI to be those which evolution has optimized the hardest, and that these are the things for which there’s least variation among humans. Our intuition is that things like chess and math are hard because of how much better the best humans are than average. In reality it’s the things that everyone is equally good at, like image recognition, which evolution has optimized the bajeezus out of, that are hardest for AI to match.)
Back to Erdil’s bull case, he goes on to give a first-principles argument that there's at least a 10% chance of groping our way to AGI by 2030 by randomly exploring the space of algorithms for training a neural network as good as the human brain. If we extrapolate from present capabilities and the limitations of current AI, that's helpful only for predicting the next few years. Beyond that, we should ignore present capabilities. Unpredicted capabilities will emerge, as they've consistently done so far.
I’m not even sure the person giving the bear case would dispute that exactly. They explicitly say they’ve still got some probability mass on unexpected capabilities emerging. They’re much more reasonable than Gary Marcus.
This week in mundane utility
Tada, a new AGI Friday feature. But just to reemphasize, there’s a world of difference between cool new things AI can do today, and AGI, whenever that happens. AI in 2025 is pretty wild and exciting and fun (and, sure, often over-hyped). What might be coming next decade — AGI — is that times infinity, or times negative infinity. New toys are great. AGI we are not ready for and is genuinely frightening.
Ok, so this week, Christopher Moravec tells the story of how we play the NYT Connections game at the dining room table and we wished it’d let you drag the cards around before making a guess so we literally pasted a screenshot of the game into Claude and added this prompt:
We're playing Connections and we want to be able to drag the cards around before submitting them. Can you make a little app that just recreates this grid and lets the user drag things around? (That's all, nothing else about the game Connections, just the draggable cards.)
Et voila, it whips up a usable UI. Claude calls it an Artifact and even lets you make a public link to it:
claude.site/artifacts/9a4efc82-c741-4444-87f1-17452f55b9c9
(If you don’t know the game, you should click that link and try it. The goal, in our version, is to drag the cards around so each row fits some theme. There’s generally one easy one where all the cards are rough synonyms, as well as a sometimes fiendish one where you have to notice that every card is part of a common phrase with the same initial or final word. I’ll put the answer in a footnote.1)
Of course that has today’s Connections hard-coded but you can just paste in a screenshot of tomorrow’s Connections and say “hey, can you redo that but swapping in these words?” and, lo, it can.
This week in predictions
Manifold traders are quite confident we’re getting AGI in the 2020s or early 2030s:
That’s a new market I’ve created in part to pin down a better definition of AGI that won’t accidentally trigger because an LLM can fool humans into thinking it’s a fellow human for long enough. (As most of you know, that’s how the Turing test works.) To count we want to be sure it can do long-term planning and otherwise be as fundamentally capable as a human at bending the world to its will. It’s a work in progress with a whole evolving FAQ and extensive discussion in the comments already.
This week in the news
If you’re curious about OpenAI’s shenanigans with transforming itself from a nonprofit to a for-profit, Scott Alexander has the story.
Google’s new robot arms look pretty exciting, not that that’ll be a consumer product any time soon. But eventually!
Other things are less exciting. Zvi Mowshowitz has an extensive de-hyping of the latest “OMG look what this Chinese AI company can do” news cycle.
(If you see something that looks impressive and you’re not sure if it’s hype, feel free to ask. By default I’ll tend to ignore things that are mostly hype.)
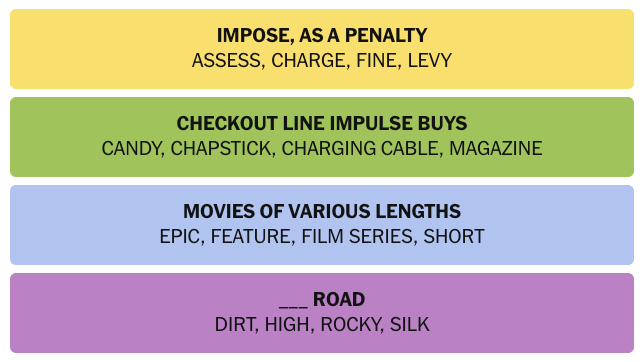
Answer to the Connections puzzle. I’m posting this close enough to midnight that hopefully no one will be upset by the spoiler.
When I was playing around with AI code before I recently started learning CS, every time I asked for a new feature another (very subtle) regression would pop up when I ran or diffed the code. Maybe Microsoft’s copilot could bring clippy back to ask, “Are your tests still passing on your code?” 🤣
Of course any real project that uses AI code is going to catch this, the problem is a situation exactly like this when you need something in five minutes and you can’t justify putting aside the time to write tests for the (sometimes literal) joke of an application you’re making, especially when the aims of the project can change so much (and the tests would change so much) and the changes you want mostly lie in CSS / layout rather than semantics.
For little projects like this, (I’m sure this might exist) it’d be nice if there’d be a deep research counterpart that writes unit tests before you spin up your app, and then rejects any AI code that doesn’t pass the tests. But at that point…