
The State of Vibe-Coding
And vibe-coding our way to probability distributions over how this AI thing may play out

Have you tried getting AI to build an app and it fell on its face or was more trouble than it was worth to argue with it about what you wanted? And when you mention as much do AI hypesters make excuses or ask if you used the latest model?
Well I’m here to tell you: are you sure you used the latest model? I’m so serious, in the last month, starting with Gemini 3 Pro on November 18 and followed quickly by Claude Opus 4.5 and GPT-5.2, AI coding has made such a huge leap in capability. You really have to try it.
(I suppose that waiting till the capabilities of these things stops improving by leaps and bounds every so many months would be a perfectly reasonable strategy, too. I’ll let you know if that happens! And if it doesn’t, you won’t need me to let you know.)
Remember the little app I made back in February? That was the second ever AGI Friday, just over 10 months ago now. Back then I was impressed that it could make something very primitive and barely usable. Just a grid with little dots you could drag around. Now I can describe features to my heart’s delight and it invariably understands what I mean and usually implements them correctly on the first try. Today I’ve been trying out Google Antigravity, which can use the keyboard and mouse to actually try out what it’s building and fix its own bugs with less of the tedious back and forth. I haven’t decided how valuable that is. I expect it to be a big deal as it continues to improve. In any case, here’s what I’ve made so far, still without touching the code:
I think it’s pretty slick. You can drag chunks of probability mass around and see all the percentages reflected, and click a button to get a snapshot. Here’s a screenshot showing Nate Silver’s original probability distribution:
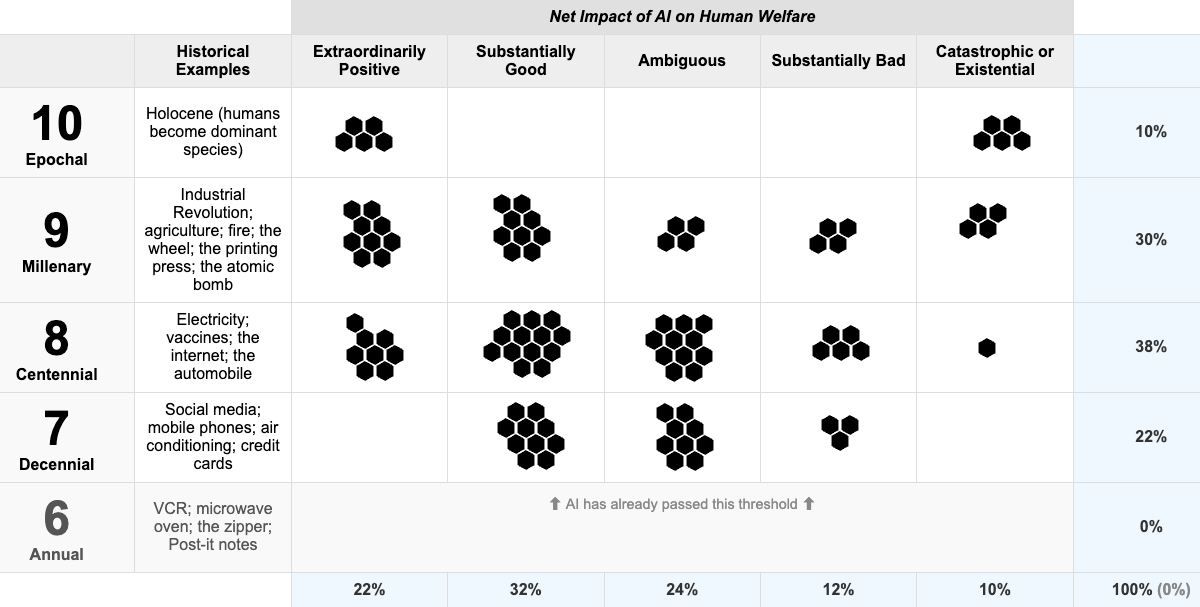
Of course where you distribute the probability depends a lot on the timescale. When I wrote about this in February, I went with “this decade”, so the end of 2029. I now think it might be most useful to be more flexible on timing and consider where we think things are heading before AI capabilities next plateau, whenever that may be. That’s also not completely satisfying; maybe AI steadily gets better and better without there ever being a clear plateau, and yet it takes 100 years to hit a 10 on the technological Richter scale.
But more likely, we either continue on this trajectory right through the world turning upside down or the bubble bursts and we have another AI winter.
Review of the risk
Speaking of which, let me review, for anyone just tuning in, the profound uncertainty we’re facing:
AI may hit a wall at something like current capabilities. For how long? Who knows.
If not, there are various ways recursive self-improvement could stall out before capabilities are too dangerous. Maybe we achieve superhuman coding but it turns out a country of
geniusesmediocre and homogeneous software engineers in a datacenter can’t actually manage to recursively self-improve. Maybe it’s prohibitively expensive to run them. Not likely but, again, nobody knows.If not, AGI bootstraps to superintelligence and there’s a wide range of possibilities for how hard it will be to keep from losing control of it. I like this graph from Chris Olah suggesting how uncertain this is:

(I’m on board with Anthropic’s view, i.e., it’s probably not super easy, and “impossible” isn’t ruled out.)
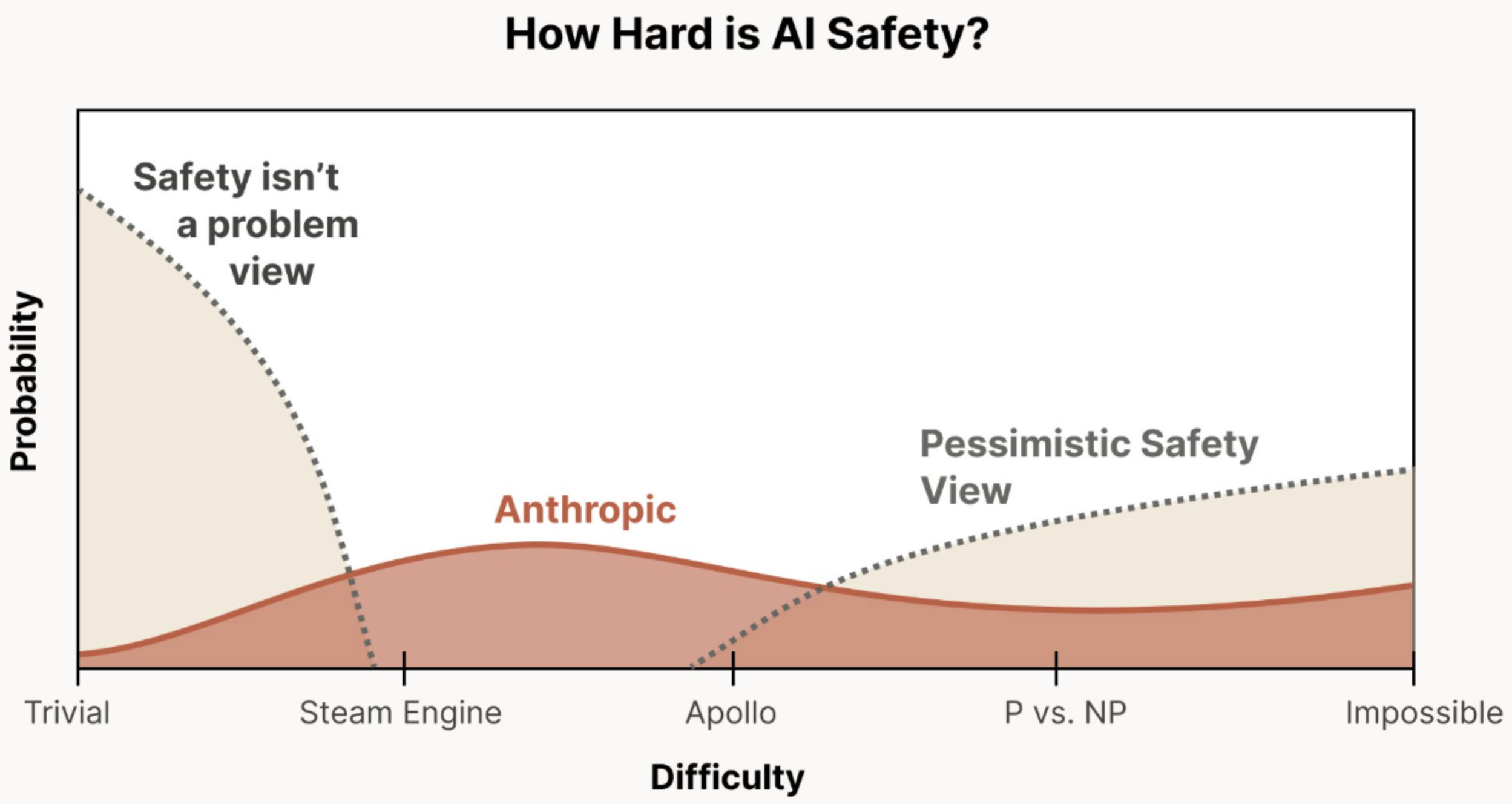
Since AI is improving noticeably by the month lately, the probability of ending up at superintellligence in the 2030s feels relatively high right now. If so, the risk of that going very, very badly is way too high.
Appendix: Coding Assistants Roundup
In case it’s useful, here’s a collection of coding assistant tools I know of today, at the end of 2025. I’ve only personally tried the first 8 in this list.
Codebuff (referral link — both of us get free credits if you sign up)
GitHub Copilot (deep GitHub/VSCode integration)
Claude Code (has VS Code extension, which is how I use it)
OpenAI’s Codex (I also use this via VS Code extension)
Google Antigravity (maybe the most “agentic”)
Google Jules (was painfully slow last I tried, but that was when it was new)
Cursor (well-funded and popular and slick)
Replit AI (cloud IDE with code assistance/generation)
Devin (well-funded, for whatever that’s worth; one of the most expensive)
Windsurf (has been recommended by people I trust, now owned by the makers of Devin but still a separate product so far)
Amazon Q Developer (recommended by GPT-5; claims a real free tier and $19/mo pro plan)
Cody by Sourcegraph (maybe now targeted at enterprise)
Aider (CLI-focused, like Codebuff)
Augment (for large codebases, supposedly; recommended by people I trust)
Lovable.dev (muggle-oriented)
MentatBot (GitHub bot that creates PRs)
Jetbrains IDE’s AI assistant (aka IntelliJ; has free tier)
StackBlitz or its subsidiary(?) Bolt.new (HT Christopher Moravec and Narthur)
Warp (recommended by friends)
Base44 (muggle-oriented)
Tabnine (recommended by GPT-5 especially when data sovereignty matters)
Phoenix.new (specific to Elixir/Phoenix)
My sense is that which of these tools you use is mattering less. You just need to make sure that the underlying model is, as of today, either Claude Opus 4.5, Gemini 3 Pro, or GPT-5.2. Consensus seems to be that Claude is best but I’m having trouble seeing a clear difference and none of those three seem to be Pareto-dominated. I would not bother with any model other than one of those three. This may all change by next week.
Love this perspecive, it's so insightful! I was just thinking the other day how I'd love to build a little tracker for my Pilates routine, and your point about the new models makes me think it's finally within reach without having to argue with the AI.
PS: I added a feature last night to make the URL encode the probability distribution. Here's Nate Silver's:
https://richter.dreev.es/?d=YgDZimq1Fd7d47
Here's what it took to implement that feature:
ME: can we come up with a clever encoding of a probability distribution? that we can put in the URL querystring? what do you suggest?
GEMINI: [describes a perfectly good approach using a 50-character hex string]
ME: how many characters would we need if we used something like base62 encoding? (is 62 the right number? how many characters can cleanly go in a URL without having to percent-encode them? 26 lowercase + 26 uppercase + 10 digits + ...?
GEMINI: [advocates for base64 encoding with dashes and underscores as well, and suggests ways to otherwise squeeze the encoding as much as possible, which of course I'm immediately nerd-sniped by]
ME: i'm intrigued. can we do even better in the common case by custom-ordering the cells? like the middle 3 cells of row 10-epochal and the first and last cells of 7-decennial are often 0 pips. all cells of 6-annual are almost always 0 pips.
GEMINI: [spits out an implementation plan that I don't read]
ME: it's no harder or messier with base62, right? i think it's a little cleaner looking without "-" and "_"
GEMINI: [stops asking questions and starts writing code]
ME: you forgot to test your code
GEMINI: [fixes its code]
ME: regression: the initial placement of pips has them overlapping
GEMINI: [fixes that]