
Extending Lines on Graphs
Looks like AGI in... *squints* 2033

Last week I mentioned that progress toward AGI, or at least toward superhuman computer programming, seems to be only slightly superexponential, to the consternation/relief of some forecasters. The metric for that comes from the impressive AI safety organization, METR: measure the difficulty of programming tasks by how long it takes human programmers to complete them and then equate an AI’s capability with the most difficult task it can do by that measure. In the last several years we’ve seen AI steadily doubling its programming capability every 7 months. The most recent datapoint from METR, for GPT-5.1-Codex-Max, is a bit ahead of that schedule. GPT can, with decent probability, successfully complete, totally autonomously, tasks that take human software engineers close to 3 hours.
We haven’t seen numbers for Google’s latest version of Gemini or Anthropic’s latest version of Claude yet but I can tell you from using them myself (especially Claude Opus 4.5) that it feels like another quantum leap beyond ChatGPT for coding. (Apparently OpenAI is panicking about this.) If you haven’t tried vibe-coding, or last tried more than a few months ago, you really should see what’s possible now. (The other day I had Claude add an automatic solver to a calendar puzzle my partner made.)
But how about a more holistic measure of AGI than just automated coding? A new paper by a huge list of impressive researchers, “A Definition of AGI” lists 10 components of human intelligence and assesses where AI is at on each of them:
General knowledge
Reading/writing ability
Math ability
On-the-spot reasoning
Working memory
Long-term memory storage
Long-term memory retrieval
Visual processing
Auditory processing
Speed
The authors assess GPT-4 and GPT-5 on each of those and come up with this visualization of how much closer to AGI we’ve gotten in the last two years:
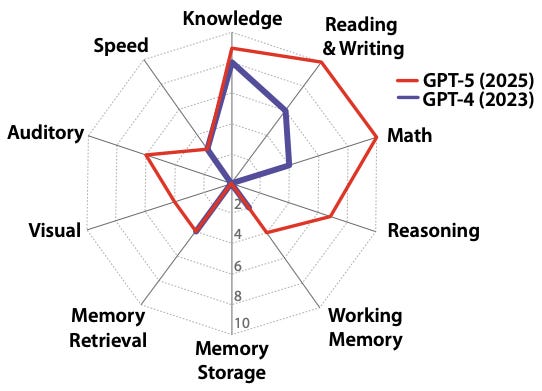
The idea is that hitting the outer edge of that circle is human level — i.e., AGI.
So that’s a nice snapshot but can we plot the progress over time and see where things seem to be heading? We can try! I had all my robot friends (ChatGPT, Claude, and Gemini) put their heads together to estimate the state-of-the-art scores for all 10 components for every year back to 2019. Their independent guesses were quite similar. I then showed each of them the others’ guesses and let them converge, which they were happy to do. I realize that’s still pretty dodgy, but rough estimates are good enough for our purposes. Here’s how it all looks:
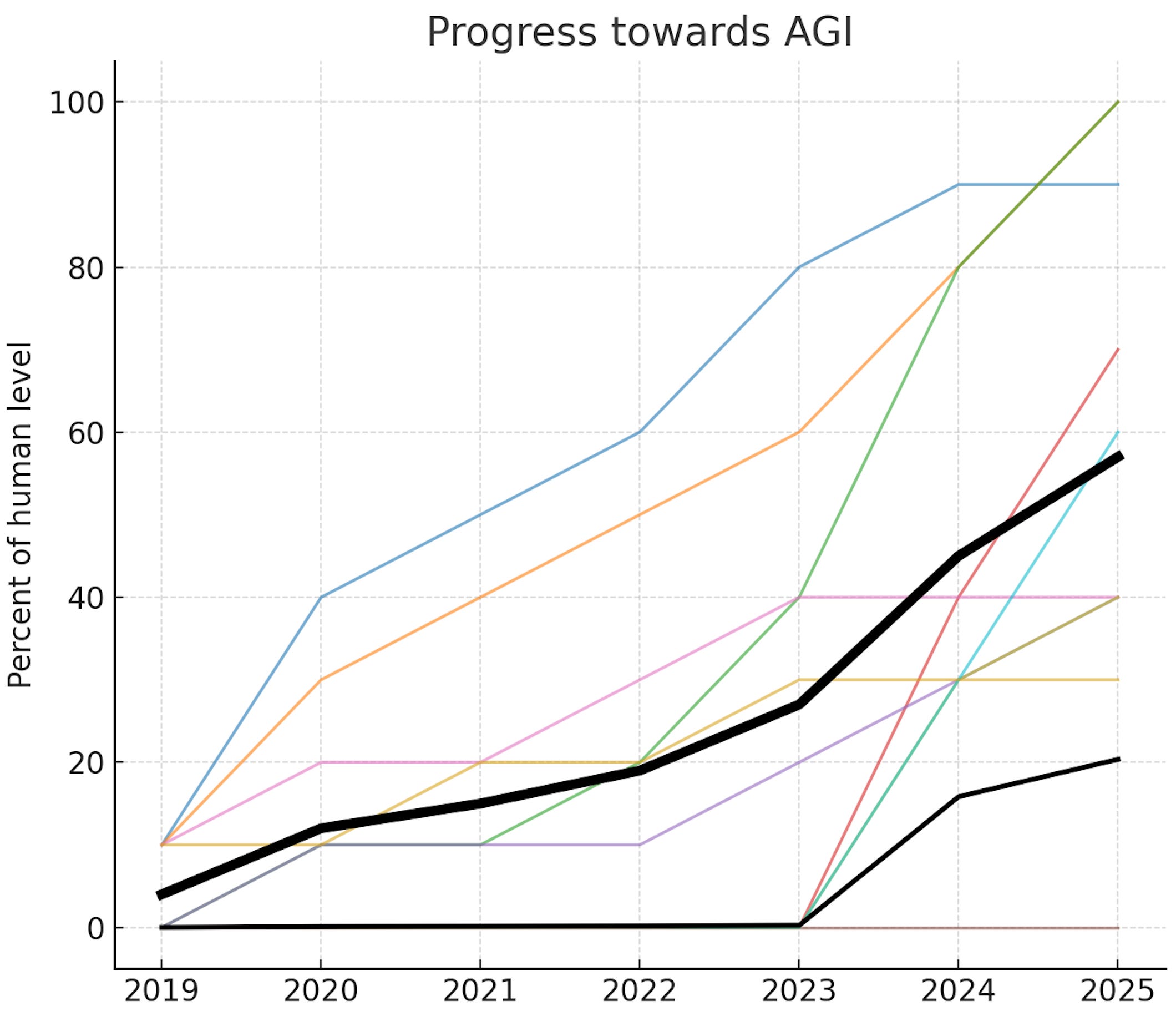

The thick black line is a simple unweighted average of the 10 component scores. That’s what the authors of the paper take as their single metric for “fraction of the way to AGI”.1 But notice there’s one component — long-term memory storage aka continual learning — for which AI is still at 0%. Presumably researchers will crack that at some point but it may require new breakthroughs.
If we were maximally pessimistic, we’d take the minimum of all the components and call that the true fraction-of-AGI value. Which would mean we’re still at exactly 0% of the way to AGI overall. What if we’re only mostly pessimistic? There’s an elegant generalization of “average” known as the power mean where you have a parameter p that you can set to 1 for a standard arithmetic mean but can dial down to get closer and closer to the extreme where you count only the minimum. I arbitrarily picked p=0.1 and plotted that as the thinner black line (notice that that changes the AGI score in 2025 from 60% down to 20%). Here’s what we get if we naively extrapolate all these lines forward:
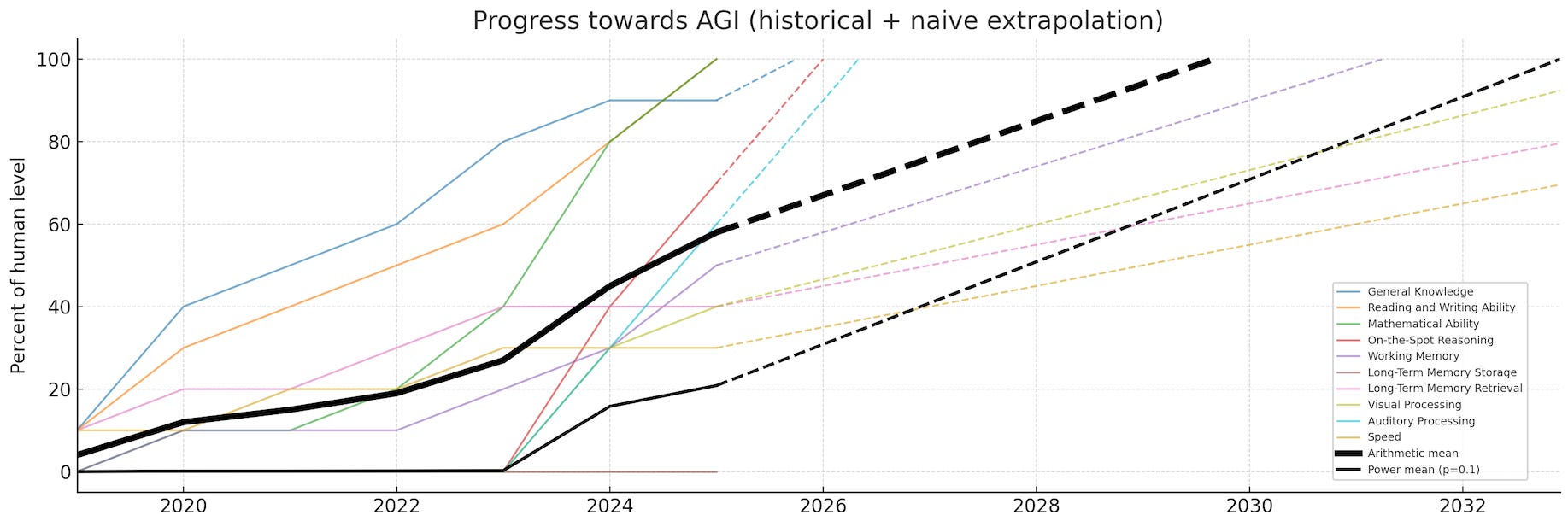
I say naively because, for starters, past performance doesn’t guarantee future results. More fundamentally, we don’t actually know if these ten components of intelligence capture everything needed for what we’d recognize as true AGI. (I think of that as a drop-in remote worker: if you’re hiring someone for a remote position, an AGI could do the job as well as pretty much any human.)
And even if those components do capture the GI in AGI, recall we’re still at 0% on continual learning. So it’s still a big question mark on the breakthrough or breakthroughs that will unlock that. (The AI 2027 folks originally forecasted it for early 2027 and more recently have pushed it to 2028. Of course others, including tentatively me, are a bit more bearish than that.)
Still, if we take this definition of AGI seriously, use the plain old average of the ten components of intelligence, and follow that line forward, we’re looking at AGI in 2029. Crazy as it sounds, I don’t think we can fully rule that out. A bit more realistically, we have an average weighted towards components of intelligence the AI is worse at, and extrapolating that line forward puts us at 2033. At this point I’d have to call that my best guess if you put a gun to my head and made me pick a single year.
This will of course continue to change. Stay tuned.
Does it matter that you can’t compress intelligence into one dimension? It really doesn’t! I have a previous AGI Friday about this.
Question from a reader, paraphrased: Isn't it a bit stingy to give current AI models a 0% on long-term memory storage? Aren't computers superhumanly good at that in a sense, and aren't there even tricks like RAGs to make LLMs able to access huge amounts of information and access it semantically, not just raw database-style searches?
Answer: A flat 0% does seem stingy, but here is how the authors of "A Definition of AGI" justify it:
[begin quote]
The jagged profile of current AI capabilities often leads to “capability contortions,” where strengths in certain areas are leveraged to compensate for profound weaknesses in others. These workarounds mask underlying limitations and can create a brittle illusion of general capability.
A prominent contortion is the reliance on massive context windows (Working Memory) to compensate for the lack of Long-Term Memory Storage. Practitioners use these long contexts to manage state and absorb information (e.g., entire codebases). However, this approach is inefficient, computationally expensive, and can overload the system’s attentional mechanisms. It ultimately fails to scale for tasks requiring days or weeks of accumulated context. A long-term memory system might take the form of a module (e.g., a LoRA adapter) that continually adjusts model weights to incorporate experiences.
Imprecision in Long-Term Memory Retrieval (MR) — manifesting as hallucinations or confabulation — is often mitigated by integrating external search tools, a process known as Retrieval-Augmented Generation (RAG). However, this reliance on RAG is a capability contortion that obscures two distinct underlying weaknesses in an AI’s memory. First, it compensates for the inability to reliably access the AI’s vast but static parametric knowledge. Second, and more critically, it masks the absence of a dynamic, experiential memory — a persistent, updatable store for private interactions and evolving contexts in a long time scale. While RAG can be adapted for private documents, its core function remains retrieving facts from a database. This dependency can potentially become a fundamental liability for AGI, as it is not a substitute for the holistic, integrated memory required for genuine learning, personalization, and long-term contextual understanding.
[end quote]
Maybe a less technical way to put that is that AI can't build proficiency by spending weeks/months/years on a problem or type of work, the way humans can.