
Rules for Agents
In which I marvel at how well AI can code, and also how much I want to strangle it

Everyone’s so cuckoo for cocoa puffs about Claude Code and kin right now. Quite correctly. My head is spinning and I might be addicted. I spent 50 hours over the holidays polishing a Calendar Puzzle game (especially the automatic solver — it’s weirdly mesmerizing to watch). It’s like English is the hot new programming language.
People are even asking if this counts as AGI. It definitely doesn’t but you can see why they ask. Collaborating with coding agents is uncannily like collaborating with humans. In some ways it’s better: AI knows everything about every programming language and is blazing fast and tireless. Being able to walk away for hours or days and then jump back in instantly without the AI batting an eye is also pretty great. In other ways it’s worse: it has horrible taste and design sense and will run with any idea no matter how wrong-headed. If you ask it to fix a bug it spews an avalanche of duct tape without ever thinking deeply about the root issue (while swearing up and down that it’s addressing the root issue). It’s infuriating and also amazing. Kelsey Piper has an extremely relatable post about how she can’t stop yelling at Claude Code.
The amazing part is that if you can describe in clear language what you want, as in writing a functional spec, AI is smart enough to build it. This is so far beyond what vibe-coding was a year or two ago (or even a couple months ago really — Gemini 3 Pro on November 18 was the most notable quantum leap since ChatGPT o3, and Claude and ChatGPT have since gotten to Gemini 3’s level). Back then we were blown away by how good the AI was at completing patterns, writing swathes of boilerplate code, and pointing you at the right libraries. Now, it genuinely understands what you’re trying to accomplish. Ok, wait, “genuinely understands” makes me sound crazy. I don’t actually want to make philosophical claims here. I just mean that pragmatically, vibe-coding now involves an utterly human-like back-and-forth with the AI. In key ways it’s just not really different from hiring a junior software developer and iterating with them on getting something built, even if you don’t know how to code yourself (though it still helps if you do).
For programmers, I’m preaching to the choir at this point. So let me end with something only they’ll appreciate. The latest contents of my AGENTS.md file that instructs my robominions how they should behave in my codebases:
UPDATE: The latest version of these lives on GitHub.
Don’t edit these rules. Only edit the scratchpad area marked below.
Before finalizing your response, reread it and ask yourself if it’s impeccably, exquisitely, technically correct and true. Have epistemic humility.
Never say “you’re absolutely right” or any other form of sycophancy or even mild praise. Really zero personality of any kind.
Never claim a bug is fixed or that the code exhibits some behavior without trying it.
I, the human, am not your QA person. Iterate on your own until your code works.
Never modify human-written comments, not even a tiny bit. LLMs will often slightly rephrase things when copying them. That drives me insane. Always preserve the exact characters, even whitespace.
Don’t ever delete human-written code. Instead you can comment it out and add your own comment about why it’s safe to delete.
Follow Beeminder’s Pareto Dominance Principle (PDP). Get explicit approval if any change would deviate from the Pareto frontier.
Follow all the standard principles like DRY and YAGNI and ZOI and KISS that coding agents seem to be almost but not quite smart enough that they go without saying. You can do it, agent! You are wise and thoughtful and pragmatic and only the best kind of lazy and you abhor code smells. I believe in you! Still zero personality though, please.
This one I have yet to find the limit beyond which being more dogmatic about it stops bearing fruit: Follow Beeminder’s Anti-Magic Principle. “If-statements considered harmful.” I mean that kind of almost literally. For example, if you’re fixing a bug like “when X happens the app does Y instead of Z”, resist the urge to add “if X then Z” to the code. Fastidiously mention every if-statement you think you need, to me, the human. In general we need constant vigilance to minimize code paths. When we do need an if-statement, we want to change the program’s behavior as little as possible. Like add an error banner if there’s an error, don’t render a different page. Always prefer to conditionally gray something out rather than conditionally suppress it.
The extreme of worse-is-better aka New Jersey style is probably too dangerous. Knowing when to deviate from the MIT approach is something of an art and requires discussion.
Beeminder’s Anti-Settings Principle may go without saying since a coding agent isn’t going to just add settings without asking.
This one is huge, on par with anti-magic: Follow Beeminder’s Anti-Robustness Principle aka Anti-Postel. Fail loudly and immediately. Never silently fix inputs. See also the branch of defensive programming known as offensive programming.
We call them quals, not tests. Use TDD I mean QDD.
This will sound silly but when generating new UI copy, error copy, help text, even microcopy like text on buttons — any words the end user is intended to read — write it initially in Latin. I, the human, will then translate it to English. The key is that the end user never reads any English text that was generated by an LLM.
I know some of those sound pretty tongue-in-cheek but I’m dead serious. This is all hard-won wisdom and seems to help, in my experience. I mean, some of these are fighting an uphill battle and I sometimes remind the AI to reread the rules multiple times a day. But it gets it, and proves it does. For a while, until it forgets again. Like I said, uncannily human-like.
Random Roundup
Yann LeCun admits to what I think reasonably ought to be called fraud at Facebook (Meta). Part of why I thought scores on benchmarks were so useless was that utterly incompetent LLMs like Meta’s Llama did decently on benchmarks. Turns out, no, they were just cheating. I’m actually hopeful (“hopeful” may not be the right word here) that there still are benchmarks that meaningfully measure progress towards AGI.
Speaking of which, we have a prediction by one of the Anthropic cofounders that in 2026 AI will beat humans on PostTrainBench, which, very roughly speaking is saying AI will beat humans at training AI. We’ve been fooled by benchmarks many times but this might mean meaningful progress on automating AI R&D which might mean hyperexponential progress toward superintelligence.
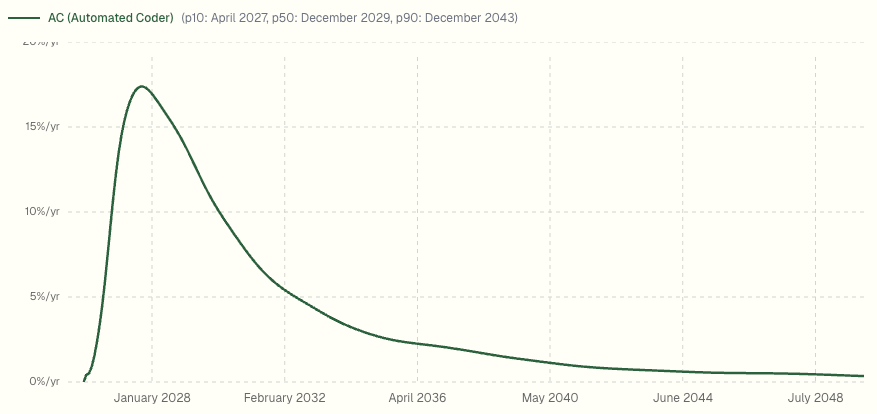
And speaking of that, the AI Futures Project (famous for their AI 2027 scenario) has updated their predictions. There are so many graphs. Here’s one of them, for when we can expect fully automated software engineering:
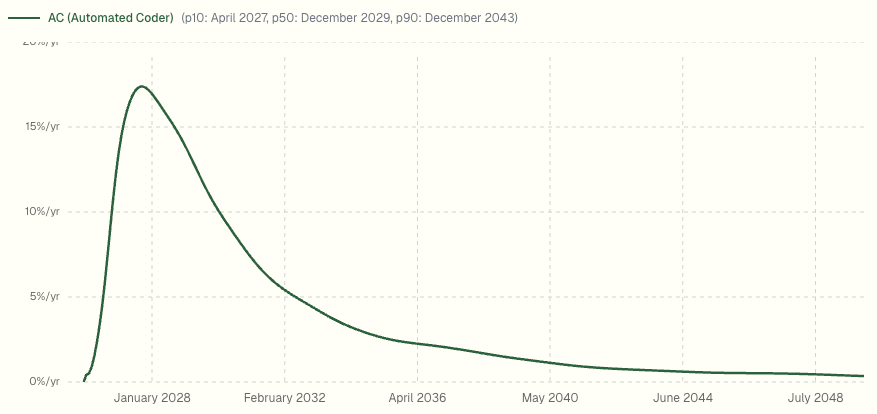
It can be hard to reason about a graph like that. On first glance it looks like “probably 2028 ish?” but if you look at the cumulative probability it’s still only a 38% chance of happening by the end of 2028. By 2036 it’s up to an 80% probability of having happened by then. For an 80% confidence interval it’s a 17-year range: that’s less than a 10% chance of it happening by mid 2027 and also less than a 10% chance of it not happening by 2044. All of these numbers feel reasonable to me.
In AI math news, my ego is relieved to report that it’s not just me, even math professors struggle to stump AI. “Struggle” may be overstating it for math professors but Mark Wildon predicts that “in a year or so, state-of-the-art LLMs [will] reliably solve almost every American Mathematical Monthly problem, and even write aesthetically pleasing proofs…” He includes this roundup of how well AI is doing on various AMM problems so far:

(He explains that the headings are short for “Could I have done it quicker without AI?”, “Did the LLM make it fun?”, and I guess the fudge factor is how much he had to nudge the AI along or fill in gaps for it.) Basically the AI was roughly math-professor-level on 6 out of 7 problems and made 3 out of 7 of them more fun to work on.
Another question I’m hearing a lot: Does AI’s ability to write most code mean our skills are going to atrophy? I see it like this:
AI is simultaneously the most powerful tool for learning since the printing press and the most powerful tool since the diploma mill for avoiding learning
Same goes for working vs pretending to work
And for generating slop vs… whatever the opposite of slop is called (can we please have a better word than “content” for this?)
This could also explain why we’re not seeing a measurable productivity boom commensurate with the subjective one that programmers are averring. I predict it’s coming though, as we figure out how to put this power to proper use.

Update: I've ditched the rule about never deleting human-written code. For one thing, it has no good way to know what was human vs AI-generated code. More annoyingly, it kept tying itself in knots about it instead of just commenting out chunks of code with "safe to delete this". It would even make messes of attempts to refactor code where it would try to move code to a new file by first copying it over but then then being unwilling to delete original. It was idiotic. Which of course is a running theme with current AI -- un utterly bizarre combination of shockingly capable and shockingly inept.
I'm also working on how to refine my "avoid if-statements" rule. Sometimes the AI will do the malicious compliance thing of writing a convoluted mess to avoid a literal if-statement, oblivious to the spirit of the injunction. Thanks to Nathan Arthur for pointing me to the concept of Cyclomatic complexity. I'm experimenting whether telling the AI to focus on minimizing that fares better.