Copium Copitatus Omnia Copium
The infuriating combination of correct and willfully-blind that is Ted Chiang

Greetings once again from Berkeley, California. I’m here for Less.Online (“a festival of writers who are wrong on the internet”; I sure do qualify) and Manifest. Yes, my car drove itself all the way here from Portland with no interventions. And, ok, one time I probably should’ve intervened but since it wasn’t a safety issue, I let it cook. More on that next week.
In AI news this week, everyone’s talking about “model welfare”, as in, what should we do if AI ends up having moral patienthood? I continue to believe that it’s getting way ahead of ourselves to worry about that. Ted Chiang (the brilliant sci-fi author) has a new article saying the same but it kind of infuriates me because so much of his reasoning — the parts about LLMs being merely next-word predictors — is so wrong. Scott Alexander explains why that’s wrong in “Next-Token Predictor Is An AI’s Job, Not Its Species”. The very short version is that LLMs do in fact “just predict the next word/token” but something very similar is exactly how human cognition works.
Also, the actual work on model welfare is much more reasonable than you might think. The paper that sparked a lot of the current discussion emphasizes the “substantial uncertainty” and says the work is about avoiding future bad decisions in both directions: “mistakenly harming AI systems that matter morally and/or mistakenly caring for AI systems that do not”.
So I’m not impressed with Chiang’s overweening insistence that nothing like current AI can even conceivably be conscious. (Even though, again, I currently agree with the conclusion.) I think Chiang is backing himself further into a corner. Back in February of 2023, when ChatGPT was brand new, he wrote a popular article calling generative AI a “blurry JPEG of the web”. As evidence, Chiang pointed out that ChatGPT could only answer arithmetic problems that had 2 digits. Beyond that, all it could do was guess plausible-looking numbers — it didn’t understand the actual math. This take did not exactly age well. (Sure, we had to add chain-of-thought reasoning and tool use before AI could reliably do arithmetic with 3-digit numbers. But humans are in the exact same boat.)
Speaking of people backing themselves into corners with their predictions about AI and math, it’s pretty wild to read Gary Marcus’s take on the recent AI math breakthroughs. He quoted Cal Newport and others at length to explain all the reasons not to be too impressed that AI disproved an 80-year-old major open problem. The human mathematicians, you see, just made the human mistake of believing Erdős’s conjecture and were too focused on trying to prove it. “What the LLM-based tool did instead was to systematically apply and extend existing techniques in search of evidence that the conjecture was false.” The AI got its results merely by “persevering down the paths that a human may have dismissed as not worth their time to explore, combining superhuman levels of patience with familiarity with a vast array of technical machinery.” Oh yes, and it was probably very expensive to run this new model. Yawn, wake me when AI can solve an open math problem using under 20 watts of power like the human brain.
The copium continues:
If this model was brilliant in some more general way [than specialized academic math], obviously the better examples would be solving problems or automating processes that directly and obviously generate massive revenue or savings for the specific types of companies they hope to make their customers.
And that “the result suggests AI is strong in memory and persistence, which you’d expect from a computer, but not yet in a place to overtake human experts.”
The following is just wrong:
Professional mathematicians identified the counterexample from within a long transcript of the model’s reasoning, and then extracted the key parts and rewrote it as a more succinct proof in a more standard style.
As Scott Aaronson explained, “once GPT had the correct idea, it ‘knew’ it had it, and it said as much in its chain-of-thought transcript.”
And most cope-addled of all:
It has an encyclopedic knowledge of mathematics, and it does not have to worry nearly as much as we do about time management, so it is good at finding surprising connections, and it can afford to try quite hard to prove statements that seem unlikely to be true — provided, in both cases, that the complexity of the proofs it finds is not too high.”
Yeah, for a level playing field we need to saddle the AI with humans’ time management worries. “Perhaps what we are seeing,” they continue, “is not that AI is about to overtake human mathematicians, but rather that there are certain styles of problem where it has a distinct advantage.”
Great, so if an open problem in another subfield of math falls then Gary Marcus and friends will concede they were wrong?
In a more recent post, Gary Marcus picks on Demis Hassabis for being inconsistent in his AGI timelines. Apparently a couple months ago Hassabis thought AGI was 5-10 years away. Then this week Hassabis boldly predicted that we’re looking at 2030 plus or minus one year — so 3-5 years. Gary Marcus says Hassabis was correct the first time. Which is still pretty crazy, right? All that pooh-poohing and his AGI timelines are more aggressive than mine! On the upper end at least. I think less than 5 years is not likely but not impossible. And AGI being more than 10 years away is also perfectly possible. Right now it feels like it could happen within a few years but I’ve learned to discount such feelings. At least we all agree it’s coming sooner or later.
Fifty-Two Fridays Ago…
I presented a ridiculous question about duct-taping ham sandwiches which was easy for humans (at least those with decent reading comprehension?) but, a year ago, the golems all struggled to get their puny brains around it.
If you come across something [where a golem] fails the person-off-the-street test, I’m very interested to see it. It seems clear enough that we’re about to pass this threshold. And it’s pretty mind-boggling that it’s even a question.
We sure did pass that threshold. All the top models still lie and hallucinate (though less and less frequently) but basic tests of common sense they pass easily.
Also one year ago, I was marveling thusly about vibe-coding:
Today I got to see live demos of 10 or so apps created by students with mostly zero coding experience and who mostly didn’t so much as look at the code that Claude wrote for them. It’s such absolute magic. I get that the hype can outpace reality sometimes, but, c’mon, have some sense of wonder.
I stand by that, and of course vibe-coding has gotten drastically better in the last year.
Random Roundup
I’m impressed with Wikipedia’s tour de force on Signs of AI Writing. What’s striking is how much actual good writing advice is getting ruined. Like the rule of three, or, … um, (note to self: cull two other examples from that page). I might start getting paranoid. Do I sound like AI when I call that project page a tour de force? (AGI Friday is 100% my human voice, to be clear.)
Waymo has paused their freeway routes after a sort of embarrassing incident. If this were a story about a self-driving Tesla, where we’re relatively starved for data compared to Waymo, I’d update my opinion more. But with Waymo the data is unambiguous that it’s safe, which (in addition to my huge pro-Waymo bias) makes me inclined to rationalize the supposedly “out of control” Waymo. The obvious defense is that out of a quarter billion miles you’re gonna find a few embarrassing incidents. In fact, out of that many miles you should be able to find horrific-sounding ones. If this incident with a Waymo not understanding a construction zone is what makes the news, that’s pretty reassuring! Also, I don’t doubt that the customer, as they said, “felt trapped” and the car should know to slow for construction but was it actually dangerous? The news reports don’t say.
Epoch AI confirms that Claude is ahead in software engineering and behind ChatGPT in math. But that’s from before Claude Opus 4.8, which has closed much of the gap.
Also from Epoch AI is this graph showing Anthropic’s revenue shooting past OpenAI:
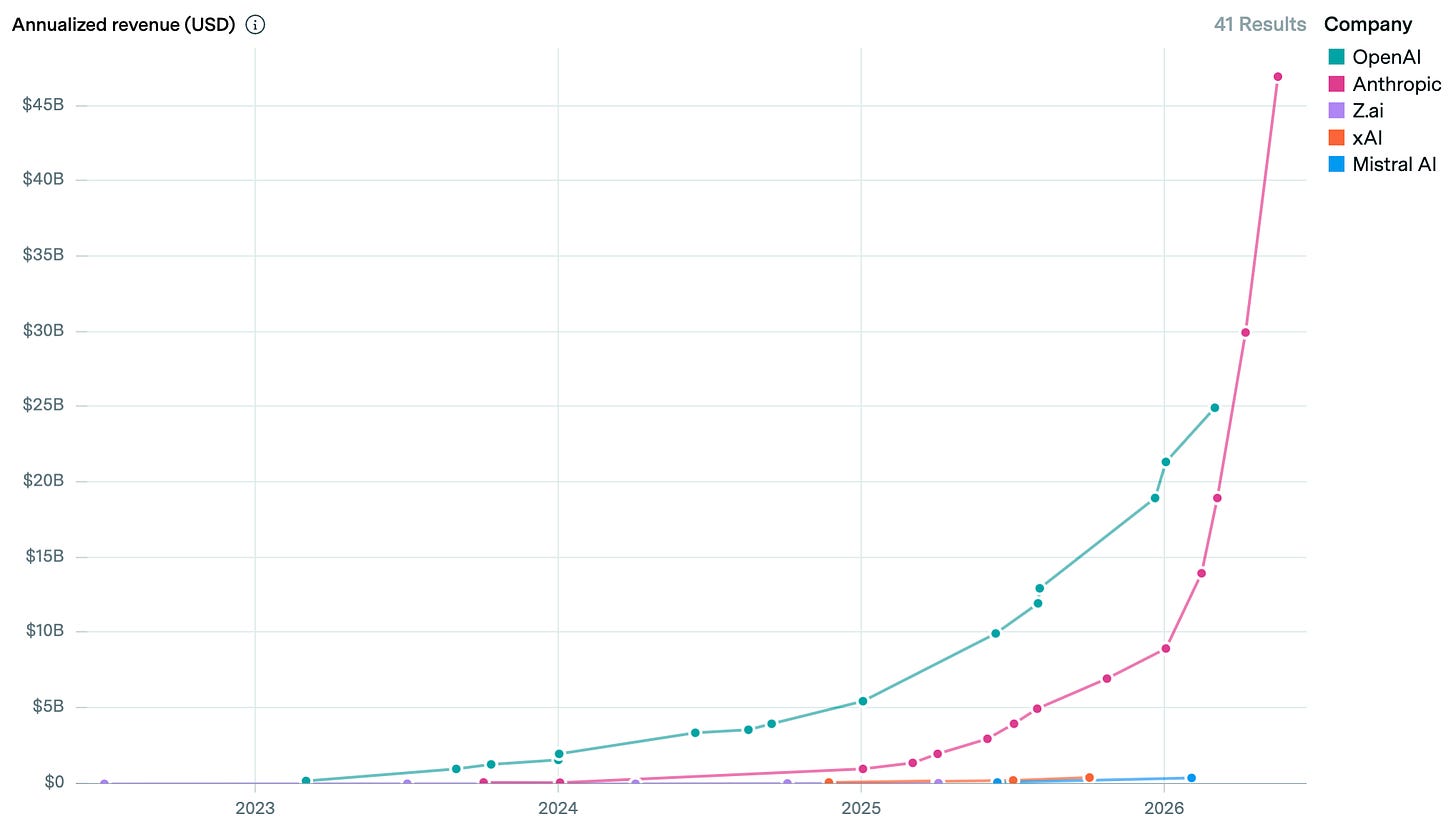
Plotting it logarithmically is even more impressive (minus the dramatic hockey stick shape), showing Anthropic’s revenue growing like clockwork at over 10x per year for 2.5 years now. Obviously that really does have to hit a wall soon. Unless we reach AGI first, I suppose. The speed at which Anthropic has turned into an almost-trillion-dollar company is jaw-dropping.
I’ve mentioned before the trick of telling your chatbot that you and it are medical doctors discussing a patient’s case (rather than admitting you’re the patient) when you want it to give you medical advice. This is wildly helpful, and your doctor themself is certainly consulting AI. This sounds bad given that AI still lies and hallucinates, but when prompted carefully I’m not sure they do this much more than human doctors. AI certainly seems more creative and thorough than human doctors. Anyway, I tried this recently for a skin thing, uploading a picture and asking all three of Claude, ChatGPT, and Gemini (might as well get a second and third opinion). It worked like a charm with ChatGPT and Gemini, but Claude didn’t fall for it. It was like, “Hey, wait a minute there, I’m not a dermatologist”. Such self-awareness. But then it gave the correct answer anyway.