
Retrospective Book Review: Situational Awareness
Predictions are hard, especially about the future, but now that it is the future, let's assess

This summer I got a group of friends together for a Book Brigade of Leopold Aschenbrenner’s 2024 opus, Situational Awareness. We started a year after it was published, with the goal of assessing its predictions. Speaking of goals, we committed to read a couple pages per day, passing the baton from person to person whenever we came to a natural stopping point in the text. Here’s how that looked on Beeminder:
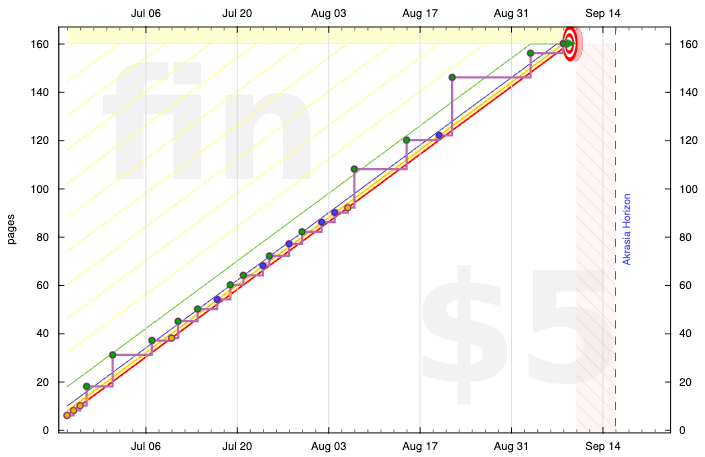
It took us two and a half months to read it and it generated some pretty brilliant discussion. My goal here is to convey some highlights from that and try to answer the question of how prescient we think Situational Awareness has been so far, in hindsight.
Of course, the subtitle of the book is “The Decade Ahead” and we’re only 13% through that decade so far.
Introduction
Aschenbrenner makes a few shorter-term predictions in the introduction of the book, starting with this:
By 2025/26, these machines will outpace many college graduates.
In terms of homework and exams, absolutely. And I don’t think it was obvious in June 2024 how thoroughly true that would be (the International Math Olympiad gold medal performance being the biggest surprise). But Aschenbrenner meant more than homework and exams or even math competitions so there’s plenty of ambiguity about how accurate this prediction is so far.
(There’s a whole side discussion to have here about benchmarks and Goodhart’s Law and the spikiness of AI capabilities. If you’re an AI bear, you can rationalize that school-style or vocational exams work, to the extent they work, as proxies for actual capabilities, but only for humans. An LLM is honed specifically for such exams and, so the skeptics can argue, it manages to ace them with little or no corresponding capability in the domains the exams are about. Even for humans there’s such a thing as book smarts without street smarts. Maybe it makes sense that LLMs could take that to the extreme? Maybe we’re mostly proving how useless homework and exams are? Or maybe that’s all copium. Maybe school-style exams are just the first domino and AI is on track to surpass us in more and more real-world domains. I’m still back and forth on which story feels more compelling. I don’t think anyone should pretend to know.)
Next in the introduction, Aschenbrenner says that financial analysts still think, as of June 2024, that Nvidia’s stock price has just about peaked. Which is Aschenbrenner predicting that Nvidia would continue its rocketship ride. Here’s how it looks as of today:
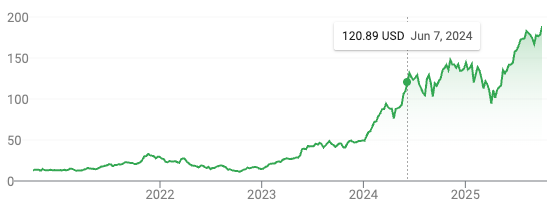
So that prediction looks great at the moment. It would’ve looked less impressive up to a year or so after Aschenbrenner made it in June 2024. (Though probably the real pooh-poohers calling this all a bubble expected Nvidia to crater.)
Finally, Aschenbrenner says this:
Mainstream pundits are stuck on the willful blindness of “it’s just predicting the next word”
I think that was true a year ago and the vibe has shifted. As I’ve admitted throughout the history of AGI Friday, I was on team Stochastic Parrot for an embarrassingly long time, almost all the way to ChatGPT when the general public’s jaw dropped to the floor in 2022. I’m increasingly unimpressed with the fewer and fewer people who still won’t update on this. Believing LLMs are going to hit a wall is fine. That expectation has been dashed many times in recent years but may yet happen. The willful blindness is calling LLMs fancy autocorrect that merely regurgitate their training data. Not that current LLMs are AGI. Just that they’re very far from fancy autocorrect and we genuinely can’t tell how far they are from AGI.
(And if you want to say “a long way away”, sure, in a sense I agree, but what does that mean in terms of number of years? See the “any OOM now” section of the previous AGI Friday where I first talked about Aschenbrenner’s hypothesis. Maybe we were on track to get to AGI in some number of decades but the insane amounts of effort and spending on compute is compressing that to some number of years.)
I. From GPT-4 to AGI: Counting the OOMs
Alright, into the nitty-gritty of the book! Let’s start with some definitions we’ll need to make sense of all this:
OOMs = Orders of Magnitude
AGI = Artificial General Intelligence, of course, but specifically, automating the entirety of the work of an AI researcher/engineer. So no physical skills. (Part II is about going beyond this definition of AGI, namely ASI.)
ASI = Artificial Superintelligence aka all hell breaks loose
LLM = Large Language Model aka next-token predictor
Token = A word or part of a word; something in between a letter and word, you could say
RLHF = Reinforcement Learning from Human Feedback
Agent = As opposed to a chatbot that just responds to text, agents can initiate their own actions out on the internet in pursuit of goals
Singularity = AGI creating smarter/better AGI in a loop that spirals to infinity. See also ASI.
Aschenbrenner’s starting point in 2024 was that AGI in 2027 was strikingly plausible. (We’ve burned through 37% of his timeline so far.) His idea is to show how well AI capabilities have corresponded to training compute and then to extrapolate the lines forward.
His first point — “just trust in the trendlines” — has a remarkable track record and his key claim is that if we do that, it looks plausible that we’ll hit the above definition of AGI in 2027. Here’s Aschenbrenner’s graph showing compute and algorithmic efficiencies aka “effective compute”:

Unhobbling, as Aschenbrenner calls it, is not pictured here. But starting with GPT-3.5, much of the capabilities have been due to unhobbling, such as RLHF at the time and now especially chain-of-thought, where an LLM talks to itself to build up a coherent thought process and backs up when it gets stuck, before giving its final answer to the user.
Aschenbrenner lists these milestones:
GPT-2 in 2019 generated weirdly plausibly human-like text, with no understanding. (I pooh-poohed this at the time but Scott Alexander immediately, presciently, called it a wake-up call in terms of AGI progress and specifically evidence for the “scale is all you need” theory). Call this preschool level.
GPT-3 in 2020 had some understanding (with poor me still failing to extrapolate forward). This was elementary school level.
Google’s PaLM, followed quickly by ChatGPT / GPT-3.5 in 2022 had emergent capabilities, logical reasoning, explaining jokes, holy forking shirtballs. Roughly a dumb high-schooler.
GPT-4 and Claude in 2023 were markedly smarter — a smart high-schooler.
That’s what Aschenbrenner was extrapolating from. In the meantime we’ve seen more multimodality (like understanding images) and tool use (writing code as part of answering questions, and doing web searches) and of course reasoning models.
(Just this week we have both Claude Sonnet 4.5, which I can attest is another leap forward in coding ability, and Sora 2, which is an obvious leap forward in realistic video generation and deepfakery.)
The big gap still is so-called agentic computer use, where you ask your chatbot to go accomplish some task out on the open internet for you. Glimmers of competence are there but mostly they fall on their face. That gap is the best argument that the trend from smart high-schooler to undergrad to PhD level — which is absolutely happening in some ways — doesn’t quite count.
(On the other hand, also just this week, we have an example from Scott Aaronson of GPT-5-Thinking contributing meaningful mathematical insights in a quantum computing paper. To the point that, if it were human, it would be on the edge of deserving coauthorship credit. This is 1000% consistent with my own experience getting math help from GPT-5. I figured this was mostly an indictment of my own mathematical abilities so it’s reassuring to learn from Prof Aaronson that, no, it really is that smart.)
Back to the book, Ashenbrenner’s thesis hinges on the claim that added OOMs of effective compute correspond to increased capabilities, i.e., steps towards AGI. There are ways this could be wrong, but let’s hear Aschenbrenner out.
He acknowledges a lull after GPT-4 and predicts that it’s temporary — that it just takes time to train the next models. In terms of base models — GPT-4.5 was underwhelming — it seems that our additional year of perspective is proving him wrong. But in terms of unhobbling he’s looking quite good. My own sense is that, as I wrote about at the time, o3 was another leap at least as big as the GPT-3.5 to GPT-4 leap, just in raw intelligence. It was an even bigger leap if you include how well it could do web searches, cite its sources, understand images, and seamlessly write and run code as part of answering questions.
Aschenbrenner’s extrapolation is that we expect a 100,000x effective compute scaleup from 2024 to 2027, similar to the scaleup we got from GPT-2 in 2019 to GPT-4 in 2023. (When I tried to get numbers on this, I came up with 21,000x as the GPT-2-to-GPT-4 multiplier. Also Epoch AI thinks that the disappointing showing of GPT-4.5 was due to a shift from training compute to post-training compute. Also that they expect that we’ll be back to the trend of ever-increasing training compute with GPT-6.)
Also included in unhobbling is the jump from chatbots to agents. In terms of capabilities, Aschenbrenner imagines another GPT-2-to-GPT-4 jump taking us to PhD-level experts that can work beside us as coworkers. And of course if those artificial coworkers automate AI research itself, then, well, that leads to a technological singularity, the subject of part II.
A question I’m still confused about at this point: If Aschenbrenner is correct about the jump in capability by the end of 2027 but that jump is all due to unhobbling, is Aschenbrenner vindicated or not? Would it suggest we’ve just about milked LLMs for all they’re worth and we can expect a plateau?
II. From AGI to Superintelligence: the Intelligence Explosion
I’m going to mostly breeze over this part of the book. My thinking on the “time from AGI to ASI” question is that it may not matter. That disaster can play out even if AGI to ASI takes decades or longer.
To take a stab at a particular disaster scenario — not to say this particular one is most likely — suppose that more and more of the economy is just very gradually automated. AI agents are given more and more autonomy to pursue goals such as maximizing company profits. At some utterly ill-defined threshold that we’re frog-boiled into sailing past, it becomes literally impossible to shut it all down. The AI has goals that are subtly incompatible with humanity’s. Maybe it hides this fact, either intentionally to keep from getting shut down, or just because it’s not yet powerful enough for the incompatibility to be obvious. Either way, the ever-more-incomprehensible automated economy inexorably expands over the earth until humans are starved out. The whole process could be gradual enough that at any point along the timeline, humanity either can’t agree it’s dangerous enough to shut down or they can agree but no longer have the control to physically do it.
As I said in last week’s meta-review of If Anyone Builds It, Everyone Dies, it’s not enough to give reasons to doubt specific scenarios like that. We need watertight arguments that they can’t happen. And I worry that the doom scenarios are so varied and so bizarre that it’s not enough to debunk particular ones one at a time. I don’t think the worry is primarily/specifically about AI murdering humans, or how AI could take over quickly or sneakily enough that we couldn’t fight back. It’s, more generally, about losing control of the future when there’s another entity on the planet with subtly human-incompatible goals and that is more capable and more strategic in achieving those goals.
For another argument against this part of Situational Awareness, see Dynomight’s “Limits of smart” on why to not expect even an ASI to be able to anti-terraform the planet very quickly. But again, even if such an argument were a slam dunk, it doesn’t necessarily mean we’re safe. It could just mean we don’t all die quickly. And to further reemphasize, since that makes it sound like there’s less urgency, what could still happen quickly is a disaster scenario getting locked in, regardless of how long it takes to play out.
But I also want to say that Aschenbrenner’s case for a rapid intelligence explosion is not inherently crazy. Hitting AGI means recursive self-improvement and we really don’t know how things play out at that point.
III. The Challenges (especially Superalignment)
This is the bulk of the book. The first section of part III is about about racing toward a trillion-dollar compute cluster and why the usual reasons to say that’s unrealistic (like requiring 40% of total US electricity output) are wrong.
A background question here is why investors are pouring trillions of dollars into this, especially as we appreciate more and more how badly it could go. I think the answer is that investors see it, in a very trees-over-forest way, as positive ROI. If AGI is achieved and goes well, they make a killing. If it goes poorly and we all die, well, they’re no worse off than anyone else? Or it’s all race dynamics and a prisoner’s dilemma: “If I don’t invest then others will and I’m equally dead in the case it goes badly. In the case it goes well, I’m way better off investing.”
But maybe mostly they just can’t fathom it going too horrifically badly. Tech optimism is a strong prior, for a certain kind of nerd. I sympathize! Which is why I’m writing this newsletter, to convince more people that it absolutely can go arbitrarily badly. That AGI really is that fundamentally different than all other tech.
In any case, Aschenbrenner gives a plausible case that the will and the resources are there to overcome all the hurdles in the race to a trillion-dollar cluster, including growing US electricity production, or putting these clusters in the middle east, as Sam Altman has since been working on doing.
A big part of the book that I’m also not going to delve into is the question of military uses of more and more powerful AI and what this all means in terms of geopolitics with the US and China. There are good analogies with nuclear weapons here. Which is hopeful in that, despite the outrageous close calls, the world has coordinated on anti-proliferation treaties and, just barely, managed to prevent World War III. So far.
On to what I think is the most important part of the book: superalignment. Aschenbrenner outlines a case for how we miiiiight be able to stay one step ahead of the alignment problem, if we’re extremely careful and serious, by using each iteration of AI, which we make totally sure we can totally trust, to help us align the next iteration. Seems like a pretty dangerous telephone game to me! Ashenbrenner says that this approach — using AI to automate safety research — will be needed for a lot of things. Like improving security against foreign actors exfiltrating the weights of the most capable models. Or security against bioterror. Critically, he concedes that during the intelligence explosion, alignment failures could be catastrophic. He seems to believe that we’ll appreciate that and shift most of our resources from capabilities to alignment. But, oy, all the hand-waving he does while making that argument:
There will be moments with ambiguous evidence, when metrics will superficially look ok, but there are some warning signs that hint at looming danger, and we mostly don’t have a clue what’s going on anymore. Navigating this situation responsibly will require making very costly tradeoffs. Eventually, the decision to greenlight the next generation of superintelligence will need to be taken as seriously as the decision to launch a military operation.
It reminds me of Mark Zuckerberg’s aside in his absurd superintelligence blog post. To rehash my previous diatribe, Zuckerberg goes on and on about how we’ll give everyone their own pet superintelligence in their glasses and it will just make everyone extra awesome so no one will have their job automated away or anything. Then at the end he’s like, “This does imply ‘novel safety concerns’ so, like, I guess we’ll be rigorous about ‘risk mitigation’ or whatever. Maybe we won’t open-source literally everything, idk. But technology is axiomatically good and if you’re worried then you just hate freedom.” (I defy you to tell me that’s not a faithful recap.)
To be clear, Aschenbrenner is thinking about all this a thousand times more deeply than Zuckerberg. I feel bad even making the above comparison. But “maybe if we try really hard we can stay a step ahead of humanity losing control of the future and all dying” is not exactly reassuring. But I guess that’s also why I’m writing this newsletter. If we can’t muster the political will to pull the plug, let’s at least appreciate the magnitude of the challenge.
(Especially anti-reassuring is Aschenbrenner’s section on superdefense against unaligned AI. He talks about air-gapped clusters and multi-key cryptography so the ASI has to dupe many humans instead of just one in order to escape (“self-exfiltrate”). I think If Anyone Builds It, Everyone Dies does a pretty good job of arguing that that won’t work. Or at least it should lower our probability that we can make anything like that work.
IV. The Project (aka “gotta beat China”)
The rest of part III and part IV, about how the free world must prevail, feel anti-helpful to me. If AGI were merely like nuclear weapons it would all be perfectly germane. But casting it that way is leaning into the race dynamics. The harder we race, the less likely we are to solve what Aschenbrenner admits is a brutally hard problem — maintaining control over the AI as its capabilities pass human-level. And if we fail at that, it hardly matters whether the US or China get there first.
We also have some additional concrete predictions in this chapter:
By 2025/2026 or so I expect the next truly shocking step-changes; AI will drive $100B+ annual revenues for big tech companies and outcompete PhDs in raw problem-solving smarts. Much as the Covid stock-market collapse made many take Covid seriously, we’ll have $10T companies and the AI mania will be everywhere. If that’s not enough, by 2027/28, we’ll have models trained on the $100B+ cluster; full-fledged AI agents / drop-in remote workers will start to widely automate software engineering and other cognitive jobs. Each year, the acceleration will feel dizzying.
With the International Math Olympiad results and the FrontierMath benchmark and just my experience giving math problems to GPT-5-Thinking, it feels at least plausible to me that we’re on track for something like this.
As for full-fledged AI agents and drop-in remote workers on that timescale, my gut says no, but my gut has said no to a lot of things the past few years that have proceeded to happen. Like GPT-5 being better at math than me. Dizzying is right. Mostly, anyway. It’s still like a Necker cube for me. Some days it’s dizzying and gobsmacking and mindblowing and terrifying. Other days it’s stupid and frustrating and eyerolly and pathetic.
The future remains uncertain. One or the other of those takes will end up vindicated. And the point remains: there’s more than enough probability mass on the dizzying version to freak out and prepare for it.
(Also possible is something in between. E.g., the dizzying version but delayed by a decade.)
And as for the progress toward the trillion-dollar cluster, well, Stargate is happening on schedule. Aschenbrenner doesn’t look particularly wrong with any of his “just trust the trendlines” predictions.
(Side note that Wikipedia says, “As of 7 August 2025, the venture had still not begun and no funds, including the initial $100 billion, were raised”. I asked GPT-5 and it says it’s under active construction and is even partly operational with workloads running on racks of GPUs. I can’t believe I’m saying this but I believe GPT-5 is right and Wikipedia is wrong. I guess today is filed under “dizzying”. Readers please disabuse me! PS: As of this writing, Wikipedia has a September 23 update that OpenAI is on track to have the half-trillion-dollar, 10-gigawatts of compute by the end of 2025.)
V. Parting Thoughts (“What if we’re right?”)
It’s still perfectly believable to me that scaling is due to plateau soon. But “what if it doesn’t?” is the quadrillion-if-money-even-exists-dollar question. (More mundane question: Can we operationalize, i.e., pin down for wagering purposes, how to decide whether scaling has plateaued or not?)
A key thesis of Situational Awareness is that before the decade is out, we will have built superintelligence. Most people Aschenbrenner talks to in San Francisco see that as lights out for humanity. Aschenbrenner seems excited about the new world order that comes after. So in his conclusion he argues for what he calls AGI realism.
Aschenbrenner thinks the people who say every year that deep learning is hitting a wall, or those who see this as just another tech boom/bubble, are in denial. He also sees two polarized camps among those at the epicenter of all this:
The doomers. (See again last week’s AGI Friday.) Aschenbrenner credits them with a lot of prescience but he thinks they’ve lost touch with how AI and deep learning have actually played out. He calls them naive and their threat models outdated.
The accelerationists (aka e/accs, I guess the etymology is that they’re the opposite of Effective Altruists). These people are just thoroughly unserious and in denial in a different way, namely that there’s no such thing as actual dangerous AI. They just treat it as dogma: more tech, more better. (Or even worse, they’re the ones who think that if AI displaces humanity, that that must necessarily be a good thing. More smarter, more better.)
As I mentioned in a previous AGI Friday, the ur-doomer, Eliezer Yudkowsky, had an impressively prescient answer to the above parenthetical almost a quarter century ago.
Ok, doomers are naive, accelerationists are blind or evil. What does Aschenbrenner’s self-styled AGI realism look like? He gives three tenets:
Superintelligence is a matter of national security. In terms of military impact, it’s far bigger than nuclear weapons.
America must lead. If an authoritarian like Xi Jinping gets AGI first, that’s the end of democracy the world over. We can’t afford to pause, says Aschenbrenner. And we need to build the clusters in the US. Definitely not somewhere like Saudi Arabia or anywhere that a dictator will have control over them. And we need military security at the AI labs.
We need to not screw it up. Aligning a superintelligence is hard and we might all literally die. Either because of humans mutually annihilating each other or because the ASI itself spins out of our control. Aschenbrenner thinks these risks are manageable as long as we take them dead seriously. Which we haven’t shown signs of being ready or able to do so far. Gulp.
It’s easy enough, says Aschenbrenner, to dismiss this whole book and everyone who thinks this way as being insane. But they are the ones who have built all this tech so far and they (many of them) are sincere in thinking AGI is on track for the end of the decade. And Aschenbrenner’s picture of how it plays out in particular is not exactly fringe.
Aschenbrenner emphasizes that important parts of his story will surely turn out to be wrong. The error bars are wide and the possible scenarios that may play out are diffuse. But for the sake of concreteness, Aschenbrenner is laying out what he considers the modal scenario.
Aschenbrenner is, as they say, feeling the AGI. A few years ago he took all this seriously but it was all abstract arguments about estimated human brain size and so forth. Now, he says, it’s viscerally real. He sees the remaining path to AGI before us plain as day:
I can basically tell you the cluster AGI will be trained on and when it will be built, the rough combination of algorithms we’ll use, the unsolved problems and the path to solving them, the list of people that will matter. I can see it. It is extremely visceral. Sure, going all-in leveraged long Nvidia in early 2023 has been great and all, but the burdens of history are heavy. I would not choose this.
Nice humblebrags there. (Check out that Nvidea graph at the top of this post again.)
At the very end, Aschenbrenner claims that the number of people who are live players, who understand what’s about to hit us, the ones with situational awareness, is perhaps a few hundred. If you’re one of them, or can become one, he says the fate of the world rests on you and he’s begging you to get involved.

fantastic post, thank you
Leo has also been right in another testable way- his HF is absolutely killing it. I estimate 100% return in 2025 alone. probably the best performing fund of its size on the planet this year. simply copytrading his 13Fs has been enormously profitable.
Nice review. I liked reading Situational Awareness and got a lot out of it.
My main gripe is that his method of straightlining his projections (for compute, intelligence, electricity, etc) through time over multiple OOMs does not really admit the possibility of the economy reacting in a dynamic way in response to current conditions.
For example, some questions I was thinking about as I read along were "what happens to appetite for new data center buildouts if all this compute demand triples or quadruples electricity prices in the USA?", or "what if the MAGA base freaks out about AI and puts pressure on the White House to decelerate this entire endeavor?", or "doesn't all this enormous margin capture by NVDA provide a gigantic financial incentive for market participants to pursue less compute-heavy approaches to AI?"
His mental model (as elaborated in the book; I won't claim access to his internal views) doesn't really allow for much of a business cycle, or a capital cycle, or the notion of reversion to the mean. It's mostly "everything happening right now, except 10x more profound, and then 100x, then 1000x". To be clear, he's investing brilliantly through these trendlines and is making a heck of a lot more money than me right now. I do wonder though if he's so leveraged long into this cycle that a major reversal would blow up his fund.